From governance to pipelines: crossing the aisle
"I've spent years one the side of policy and process. Now I am stepping into the shoes of the people who make the data ready and available for consumption"
 Python Data Engineering Roadmap- Generated with Google Gemini"
>
Python Data Engineering Roadmap- Generated with Google Gemini"
>
I have been working in the Data Governance and Management space for several years now. I am usually the person writing policies and standards, or defining the processes that specify how data should be managed across the business. I am the genie or magician that people want, who makes their data problems go away, or the enforcer who makes people fix data problems and relieves everyone else who should be accountable and responsible of the burden of these obligations, while still allowing them to reap the benefits of quality data.
Now don't get me wrong, I really enjoy the work I do which is why I have stuck with it for such a long time. But I am finding that Data Governance professionals talk a lot about data quality, lineage, and trust, and are good at pushing out policies and stressing processes, but a lot of the talk happens in a vacuum, from a position of making demands, disconnected from the actual mechanics of how data is acquired, transformed, and moved throughout an organization. If I tell a data engineer that their pipeline needs better lineage tracking, am I speaking from experience, or from some eye-catching visual framework that I saw posted on LinkedIn? I'll dive deeper into the data influencer or top voice fiasco in anther post.
So I am crossing the aisle and stepping deeper into world of the data engineer to understand things from a data engineer's perspective, the one working hands on with the data. This project is my attempt to close that vacuum between policy and practice. Data Governance and Data Management is more effective when the people writing the policies and standards have some understanding of the work they're governing.
Over the next several months, I will be working through a structured project building a real, end-to-end Python Data Engineering pipeline from scratch, using the Mental Health Act Apprehensions and Crisis Response dataset from Toronto Police Service which I sourced from the City of Toronto Open Data Portal. As I work through the project I will be sharing the outputs of each phase and sharing some thoughts and insights.
The project at a glance
The project is a production-style ELT pipeline, extracting data from public APIs, landing raw data, and then transforming and loading it to a database. By the end, I hope to have a containerized stack running PostgreSQL, DuckDB, ClickHouse, Streamlit, Metabase, and Grafana. I did a first pass of the end-to-end on Google Cloud which I will share about in a separate post. I figured it would be good to get experience to build on one of the big platforms that many companies use. Over the next few months I will be working on Part 2, building the project out and hosting it on my VPS.
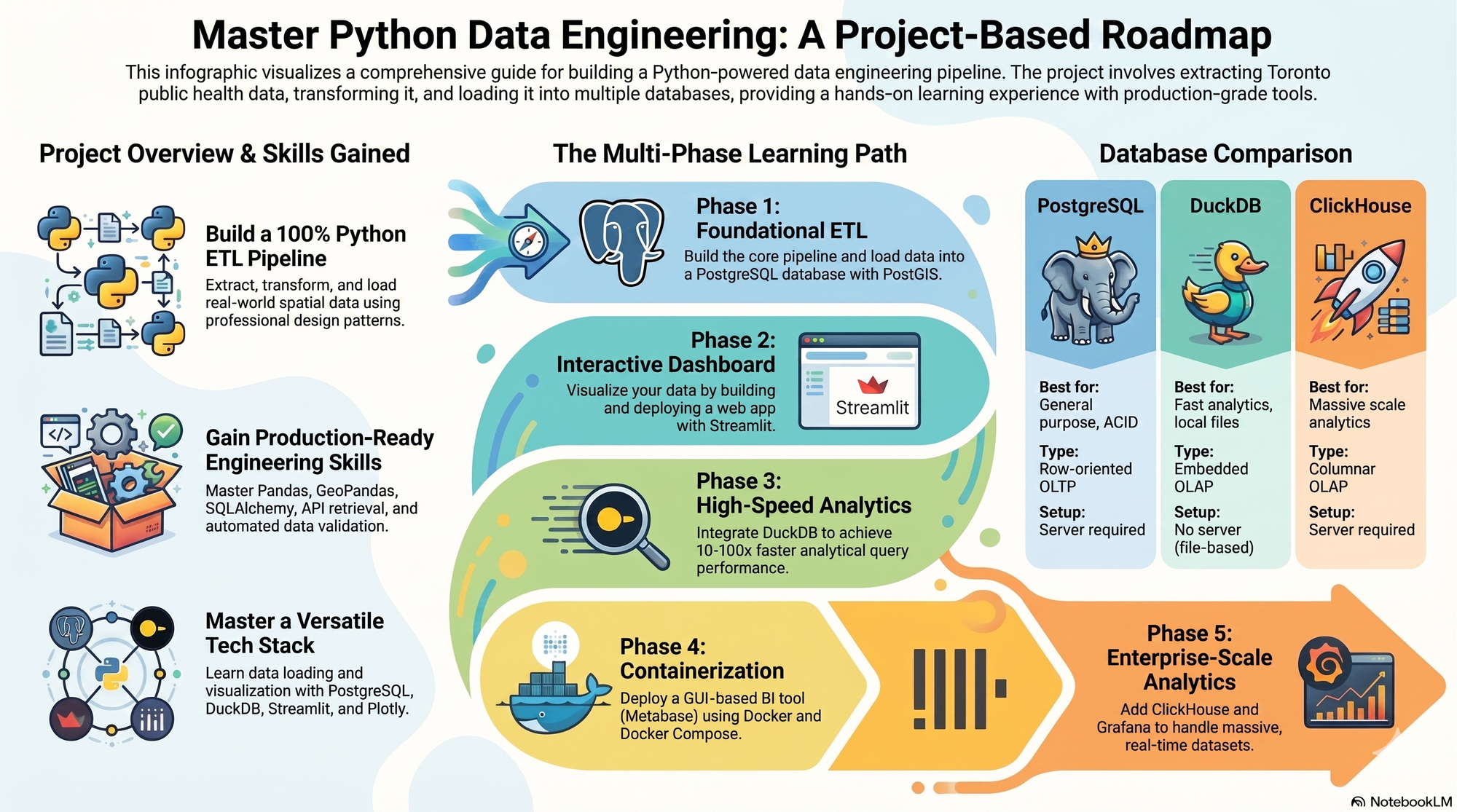
I am not unfamiliar with SQL and Python as I have used them in practice before, but I am not at an expert either. So this project also serves to up my skill level while learning new technologies along the way. Normally I would go through one of those "ultimate: from beginner to advanced" Udemy courses or tutorial videos on YouTube. However, I did not want another boilerplate course project so I decided to approach things differently by leveraging Claude AI and Gemini to plan and build out this project.
This project in reality could be completed in less than a week, including VPS setup, domain setup, and coding the pipeline. However I will be doing this over a few months because I will not be just copying and pasting and deploying code without taking the time to learn and understand what I am doing.
What to expect here
One of the things this will do is serve as my running log as I work through this project and others in future. As I complete each phase I will share what I have built, what broke along the way, what surprised me, and what it made me rethink about the governance work I do every day. In the process I will bring my governance lens to engineering decisions.
If you're a Data Governance practitioner who's been curious about the engineering side, or if you're a data engineer wondering what these Data Governance people are actually on about, stick around, hopefully both sides will learn a bit more about the other.